



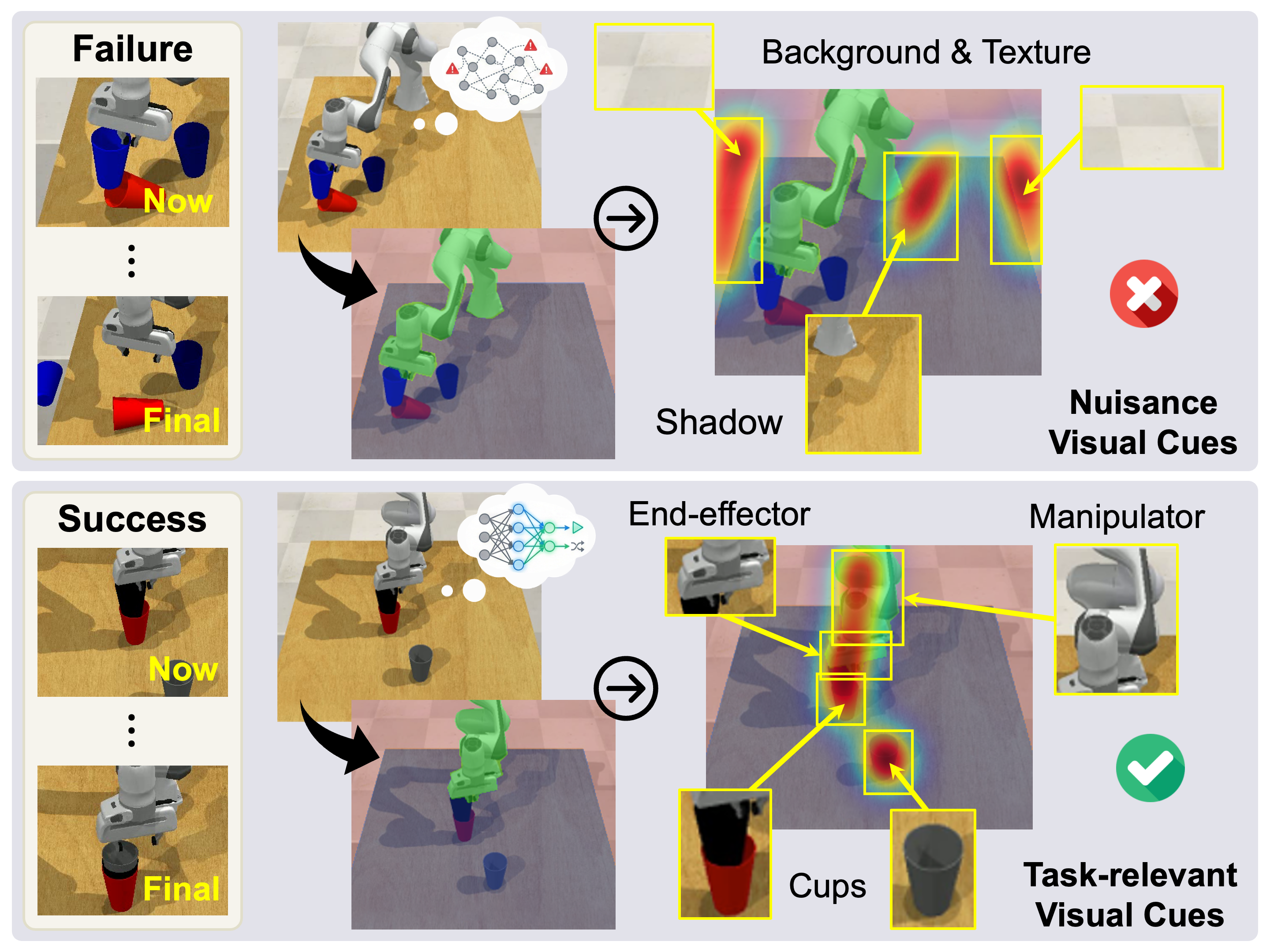
ISS
Generates heatmaps that identify visual regions affecting actions via perturbation.
"Interventional attribution reveals the causality between visual inputs and action outputs in VLA policies. Quantifying this causality enables prediction of out-of-distribution generalization."
Interpretable
Enables post-hoc explanation of VLA trials by identifying which visual regions drive the policy's action decisions.
Predictive
Predicts how well the VLA policy generalizes to OOD tasks by measuring its reliance on nuisance visual regions.
Faithful
Provides heatmaps that faithfully reflect the visual regions a VLA policy relies on for action prediction.
Plug-and-Play
Requires no changes to the VLA architecture or additional probes, intervening only on visual inputs.
Vision–Language–Action (VLA) policies often fail under distribution shift, suggesting that decisions may depend on spurious visual correlations rather than task-relevant causes. We formulate visual–action attribution as an interventional estimation problem. Accordingly, we introduce the Interventional Significance Score (ISS), an interventional masking procedure for estimating the causal influence of visual regions on action predictions, and the Nuisance Mass Ratio (NMR), a scalar measure of attribution to task-irrelevant features. We analyze the statistical properties of ISS and show that it admits unbiased estimation, and we characterize conditions under which action prediction error provides a valid proxy for causal influence. Experiments across diverse manipulation tasks indicate that NMR predicts generalization behavior and that ISS yields more faithful explanations than existing interpretability methods. These results suggest that interventional attribution provides a simple diagnostic approach for identifying causal misalignment in embodied policies.
"How can we diagnose out-of-distribution generalization failures in VLA policies?"








Two measures assess how much a VLA policy's generated actions rely on task-irrelevant visual regions.
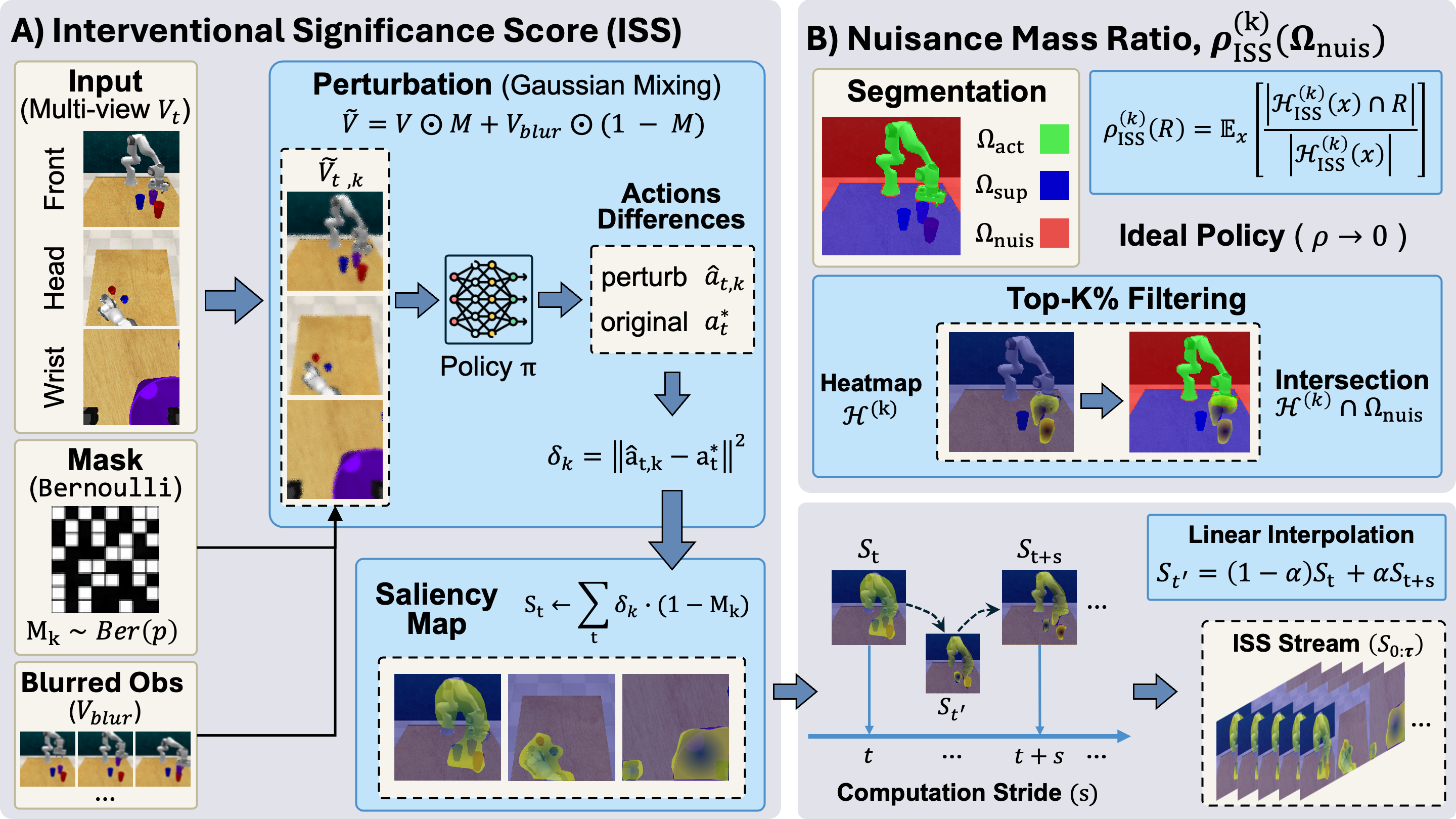
Generates heatmaps that identify visual regions affecting actions via perturbation.
Generating temporal heatmaps over entire episode via linear interpolation.
Evaluating the overlap between top k heatmaps and nuisance regions.















Four key experiments; see the paper for more details.
ISS is strongly negatively correlated with task success, making it predictive of OOD generalization.
Open result ↓ISS provides a robust result under Gaussian noise perturbations.
Open result ↓Across three nuisance region perturbations, ISS faithfully reflects how perturbations affect actions.
Open result ↓Introducing interventions does not disrupt the VLA's ability to generate correct actions.
Open result ↓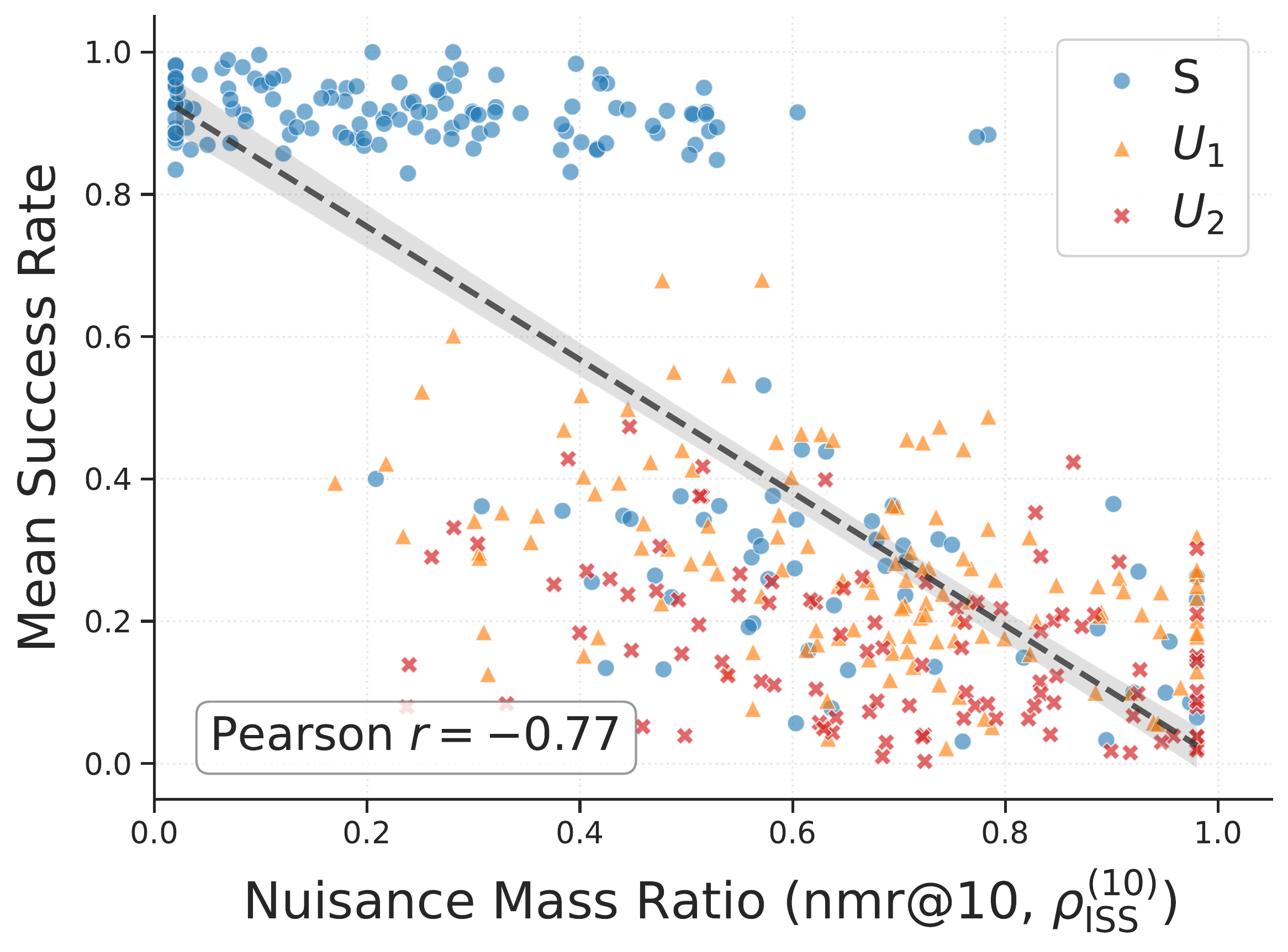
@inproceedings{zhang2026embodied,
title={Embodied Interpretability: Linking Causal Understanding to Generalization in Vision-Language-Action Models},
author={Zhang, Hanxin and Xu, Mingshuo and Dhafer, Abdulqader and Yue, Shigang and Dong, Hongbiao and Hao, Zhou Daniel},
booktitle={International Conference on Machine Learning (ICML)},
year={2026}
}